
- Published on
Stream Processing 101
- Authors

- Name
- Kaivalya Apte
- @thegeeknarrator
Note: This blog is sponsored by RisingWave Labs. Checkout RisingWave, and also join the slack channel to connect with the amazing community.
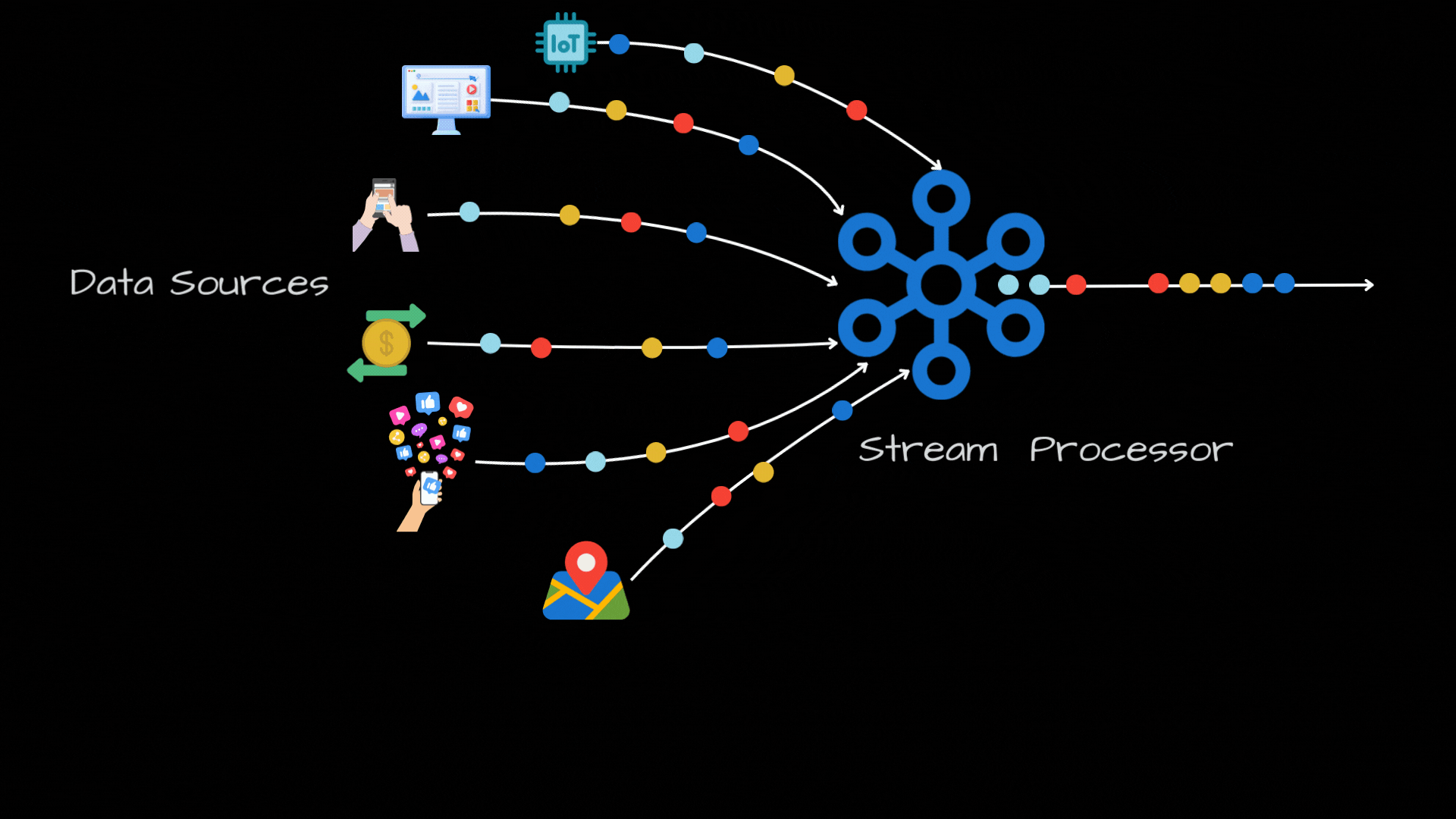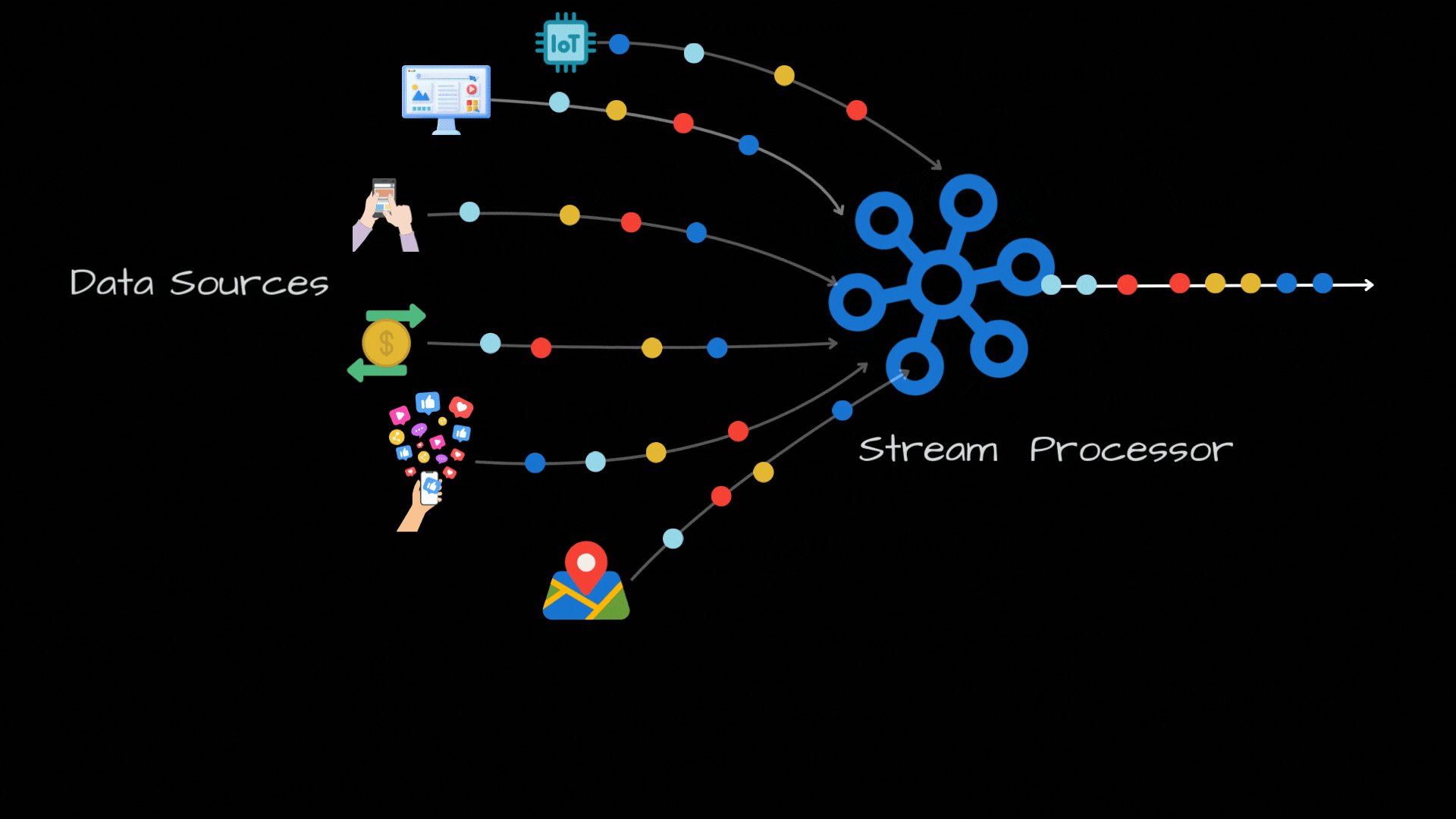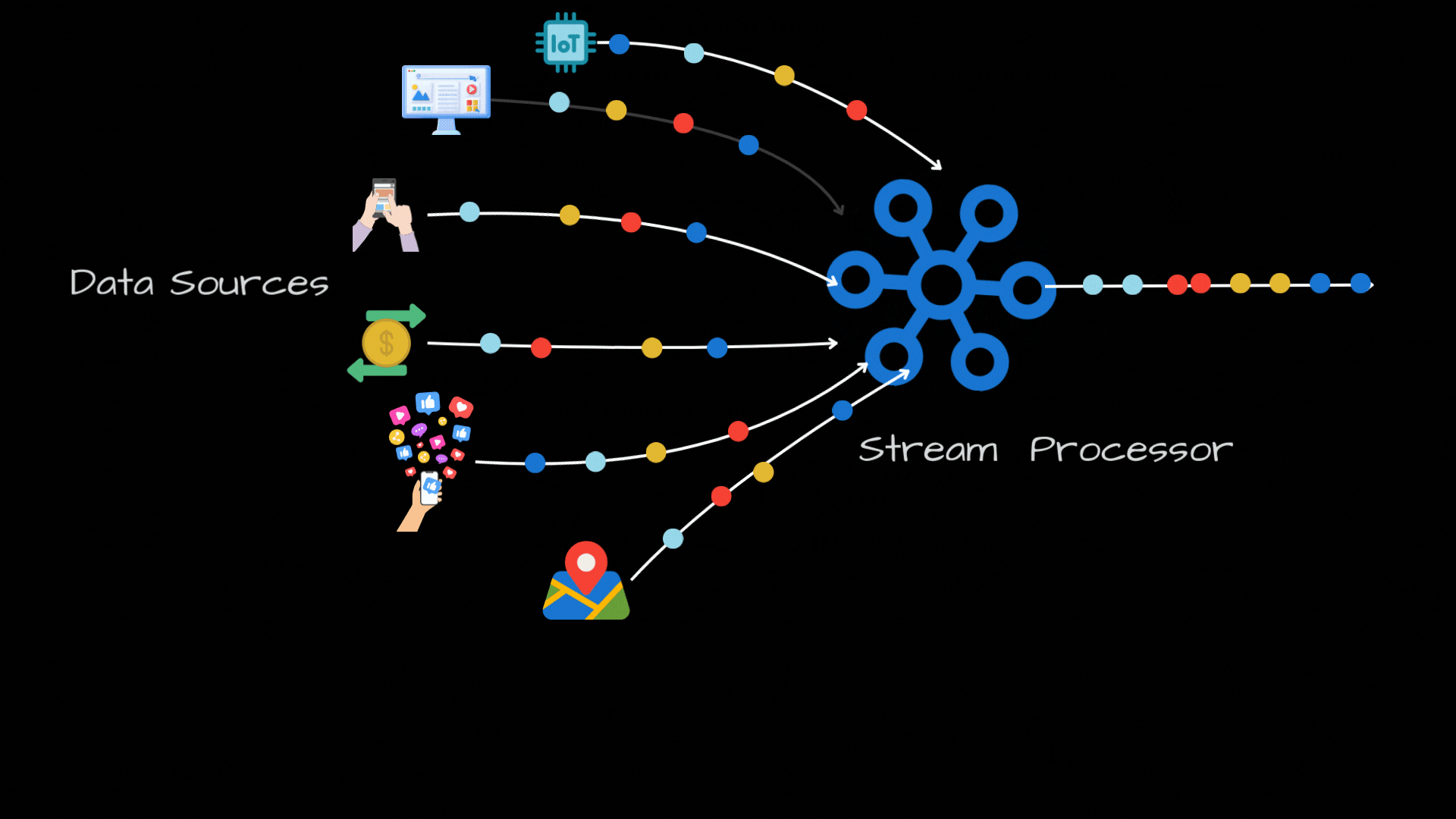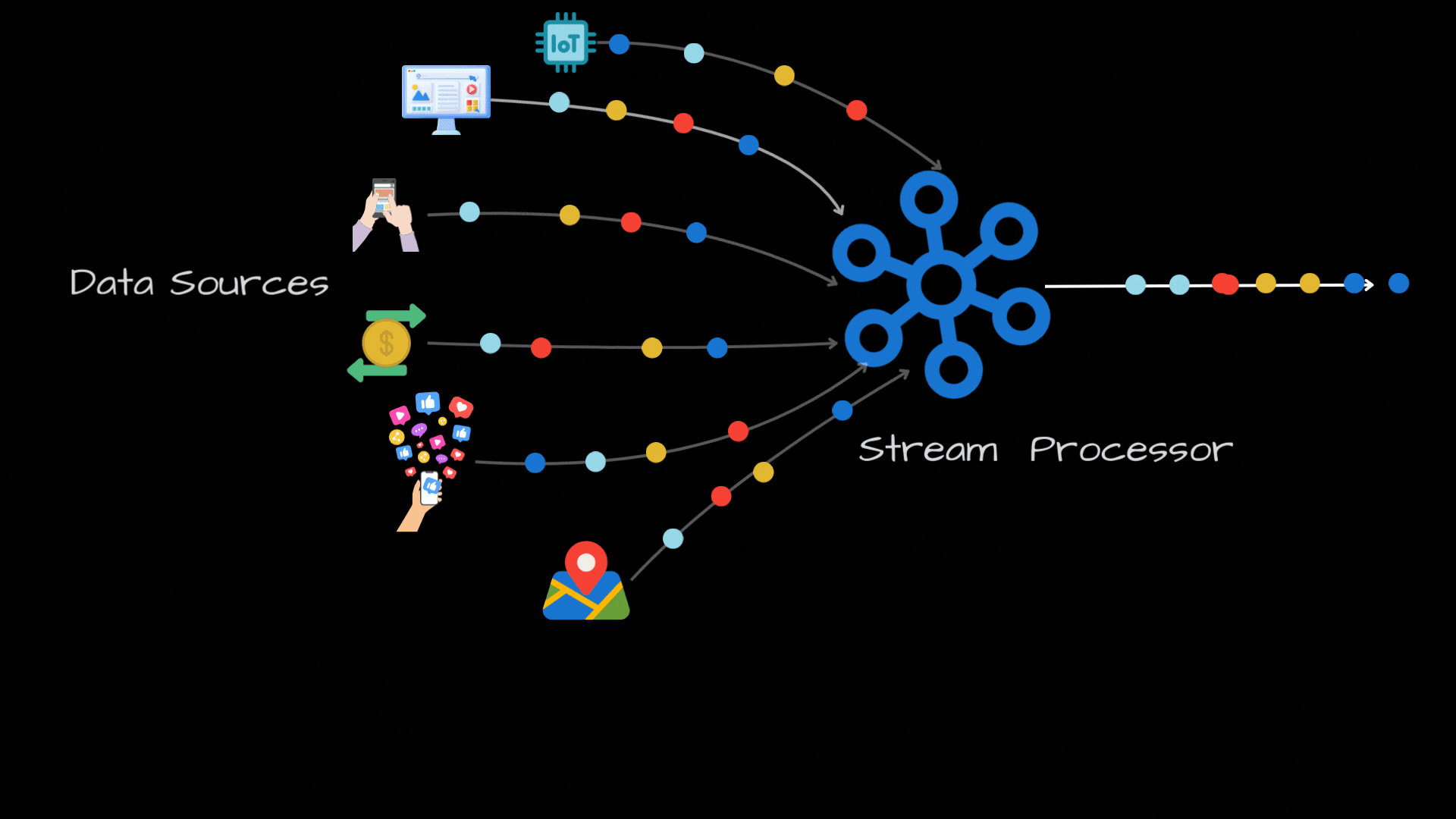
Stream Processing: An Introduction
This blog post explores stream processing, a data processing paradigm that works on data streams - continuous flows of information that may be unbounded. We'll discuss some key concepts, real-world applications, the evolution of stream processing, and how it compares to batch processing.
Understanding Key Concepts

Let's take an example of a ride hailing service like Uber, Lyft, Ola etc; and understand what some basic concepts mean.
-
Windows: This is a core concept when it comes to processing an infinite stream. Windows split a stream into
bucketsof finite size, over which we can apply transformations. Windows can be of different types like Tumbling, Sliding, Session window etc. We will go deeper into each in a separate blog. To take an example: Imagine calculating average ride requests per minute; one minute is the window in this case. -
Aggregates: Aggregates are statistical measures that summarize or give insight into a large set of data points. In the realm of a ride-hailing service, aggregates can help understand overall operational efficiency, customer behavior, and service impact. For example, calculating the total number of ride requests within a specific window or the average ride duration helps in gauging service demand and operational smoothness.
- Types of Aggregates: Common aggregates include sums (total number of rides), averages (average fare per ride), counts (number of cancellations), and more complex statistics like percentiles (e.g., the 90th percentile of ride duration).
- Utility: Aggregates are used for reporting key performance indicators (KPIs), financial forecasting, capacity planning, and understanding user engagement levels. They transform raw data into actionable insights, enabling decision-makers to devise strategic plans based on concrete figures.
-
Joins: In today's world, we have a ton of data sources, like IOT sensors, web/mobile apps, social media feeds, financial transactions, GPS trackers and so on. But, these are all disconnected, so having a unified view across these data streams is a huge challenge. Joins are really powerful as they can help us in combining different data sources based on a shared attribute. For ex: For a ride-hailing service, you can join user data with ride data to get a comprehensive view.
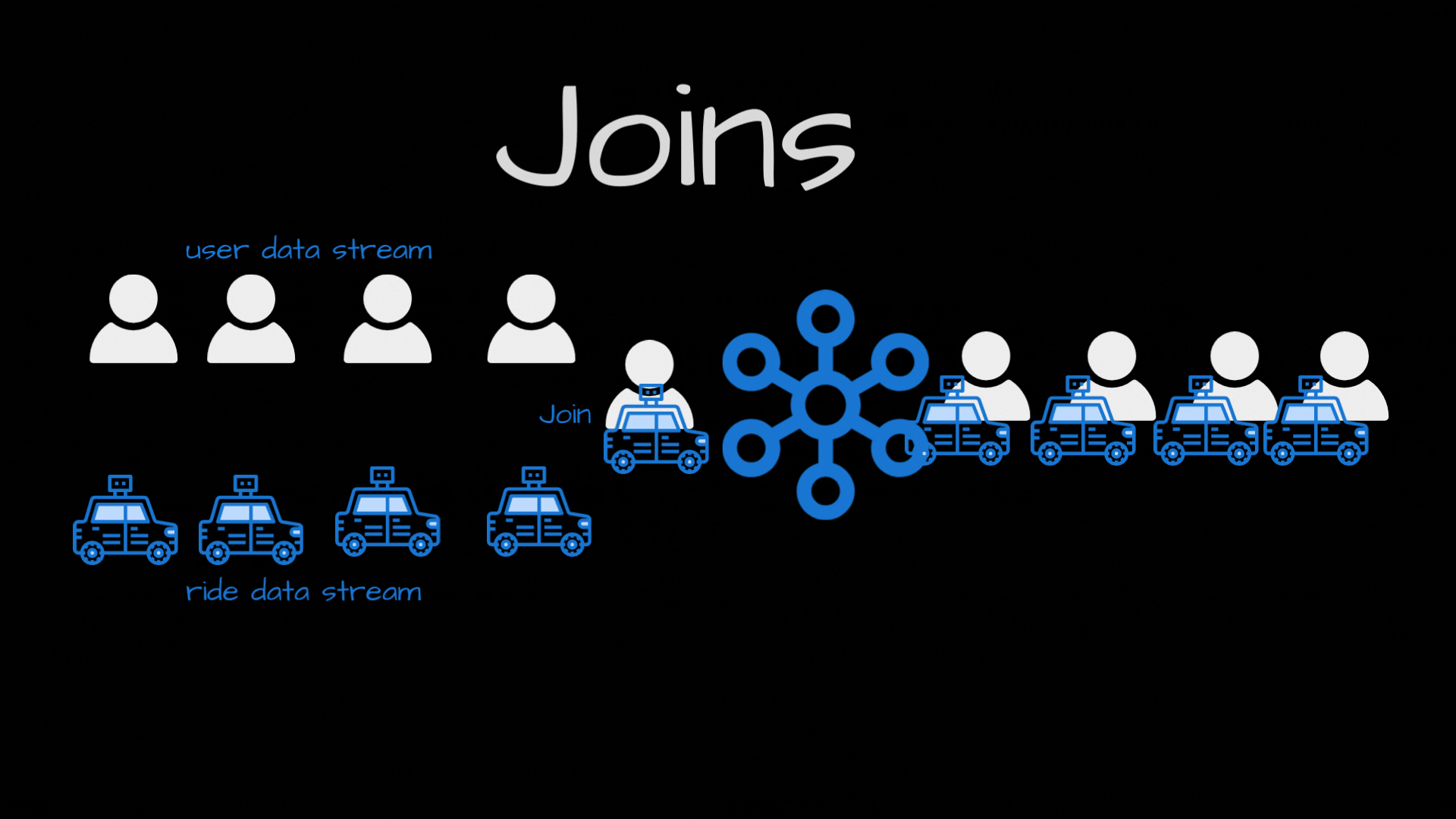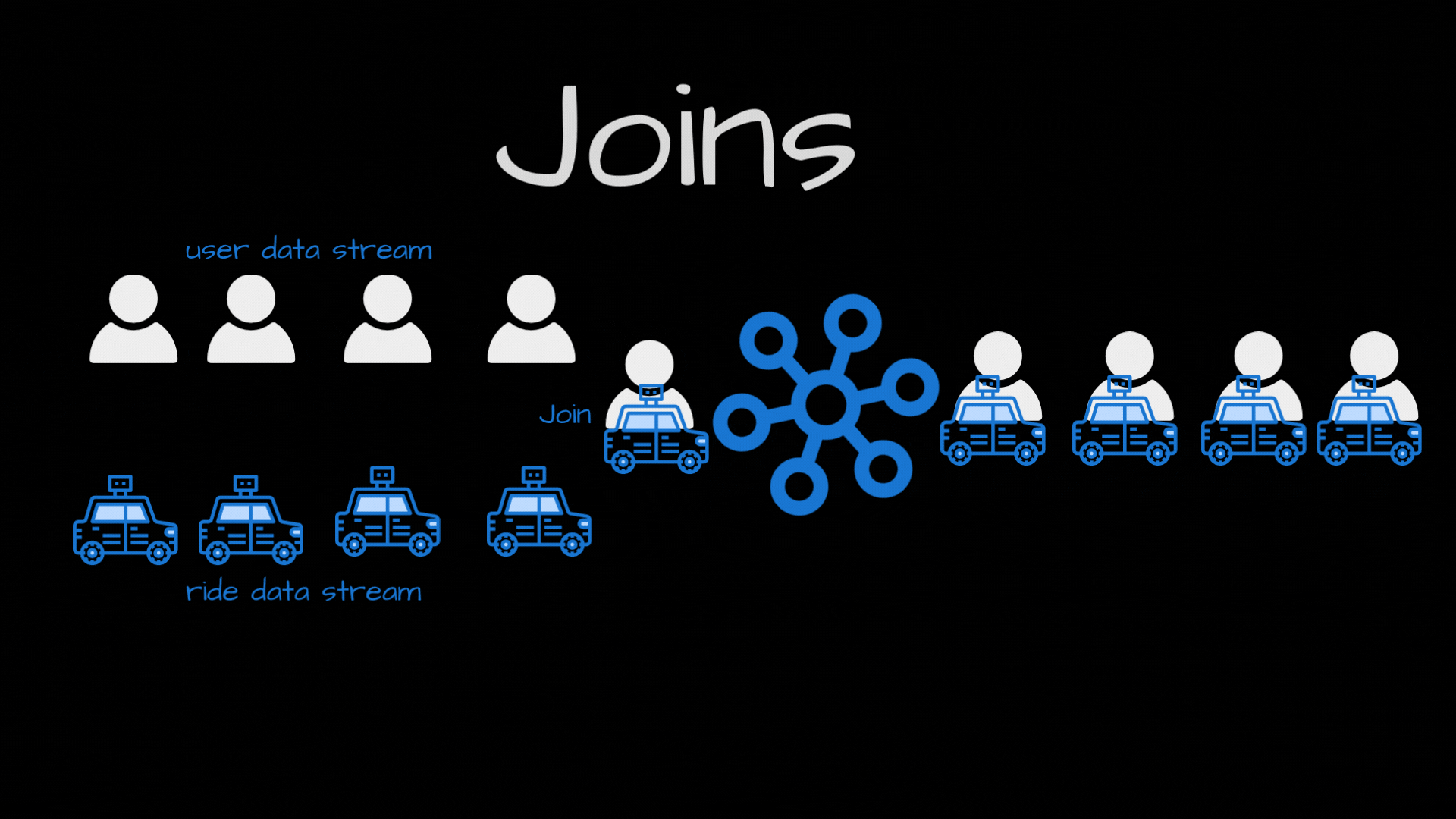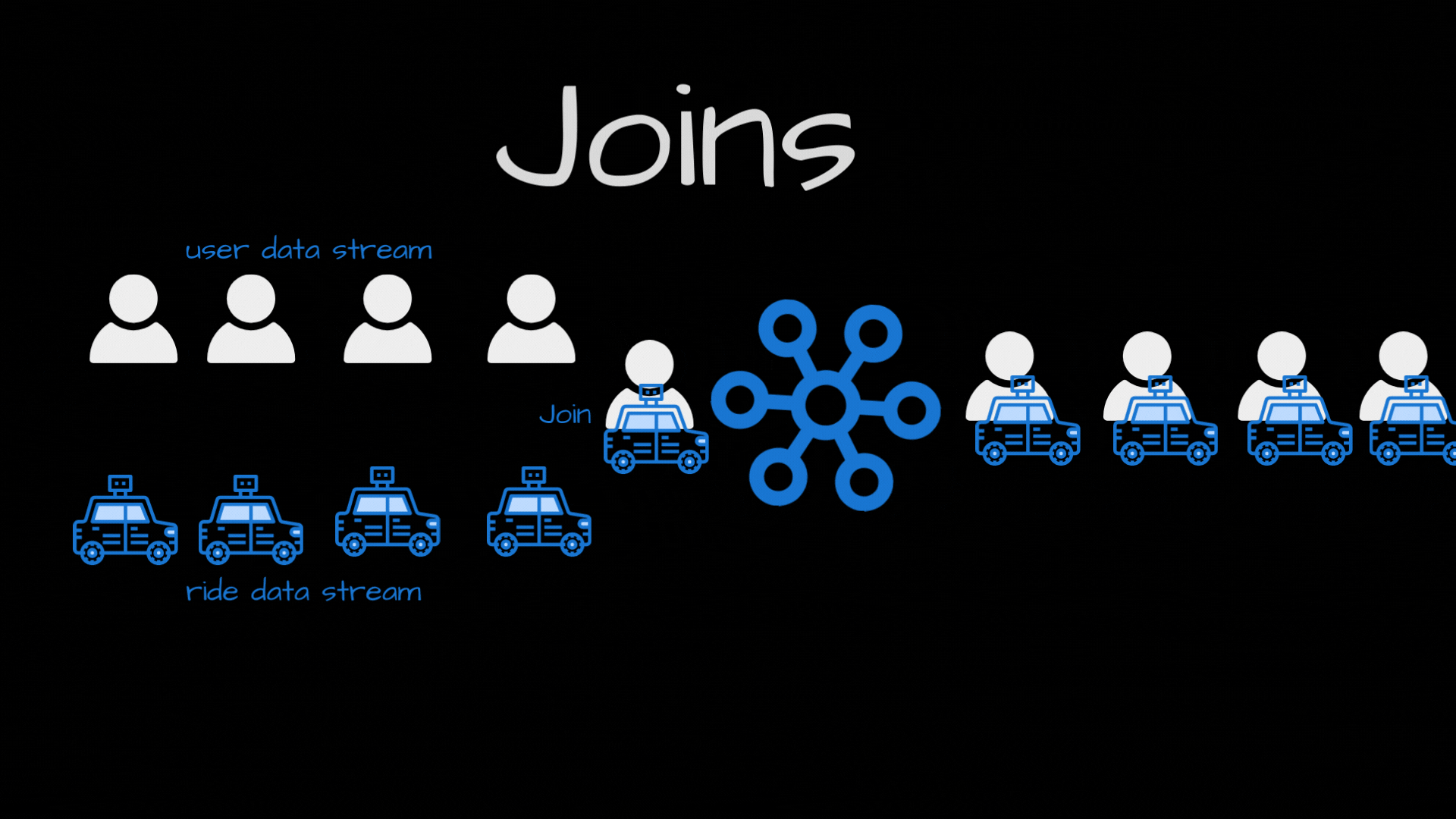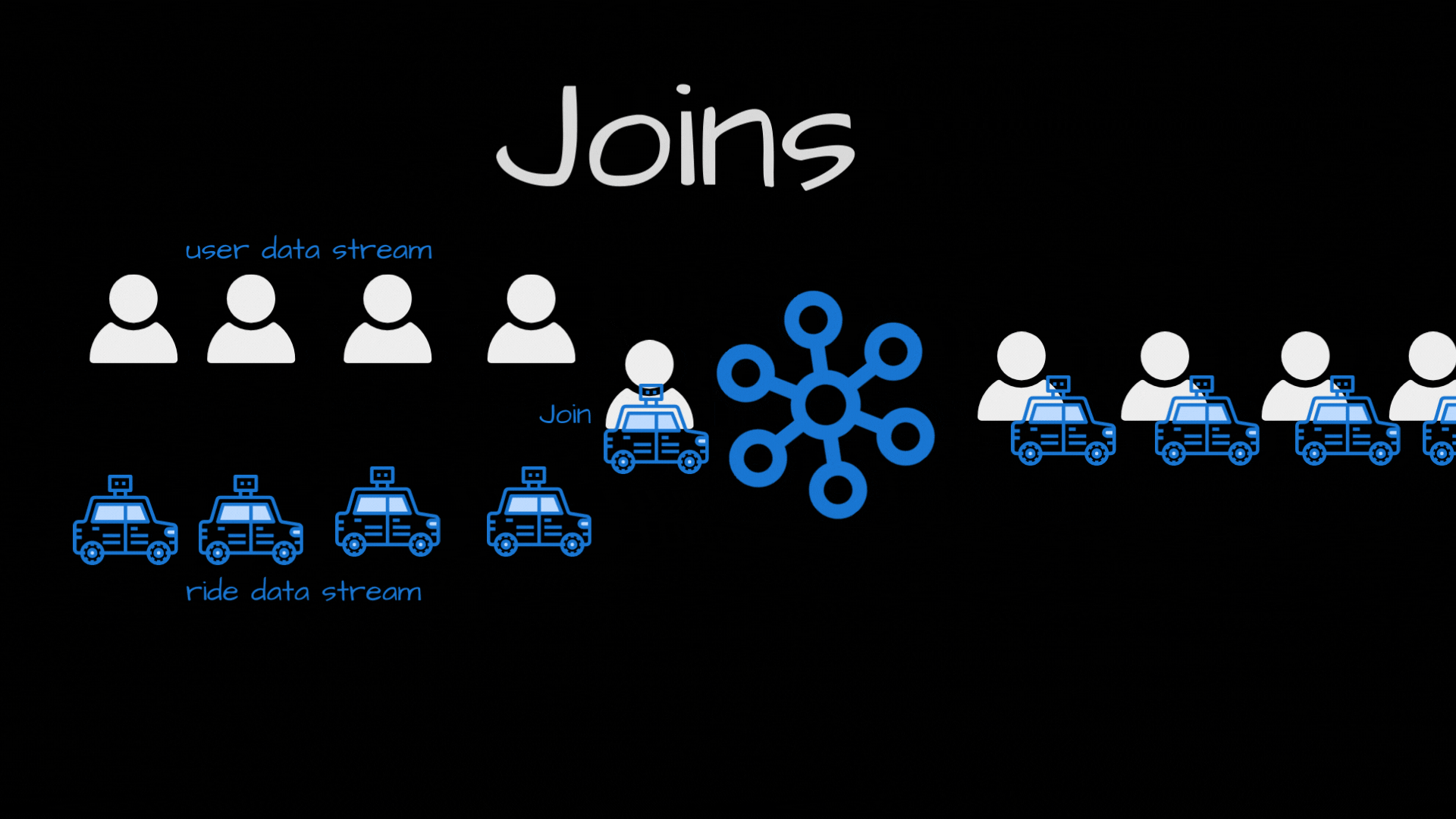
Real-World Applications
- Dynamic Car Trip Pricing: Prices can change based on real-time factors like traffic, demand, and location.
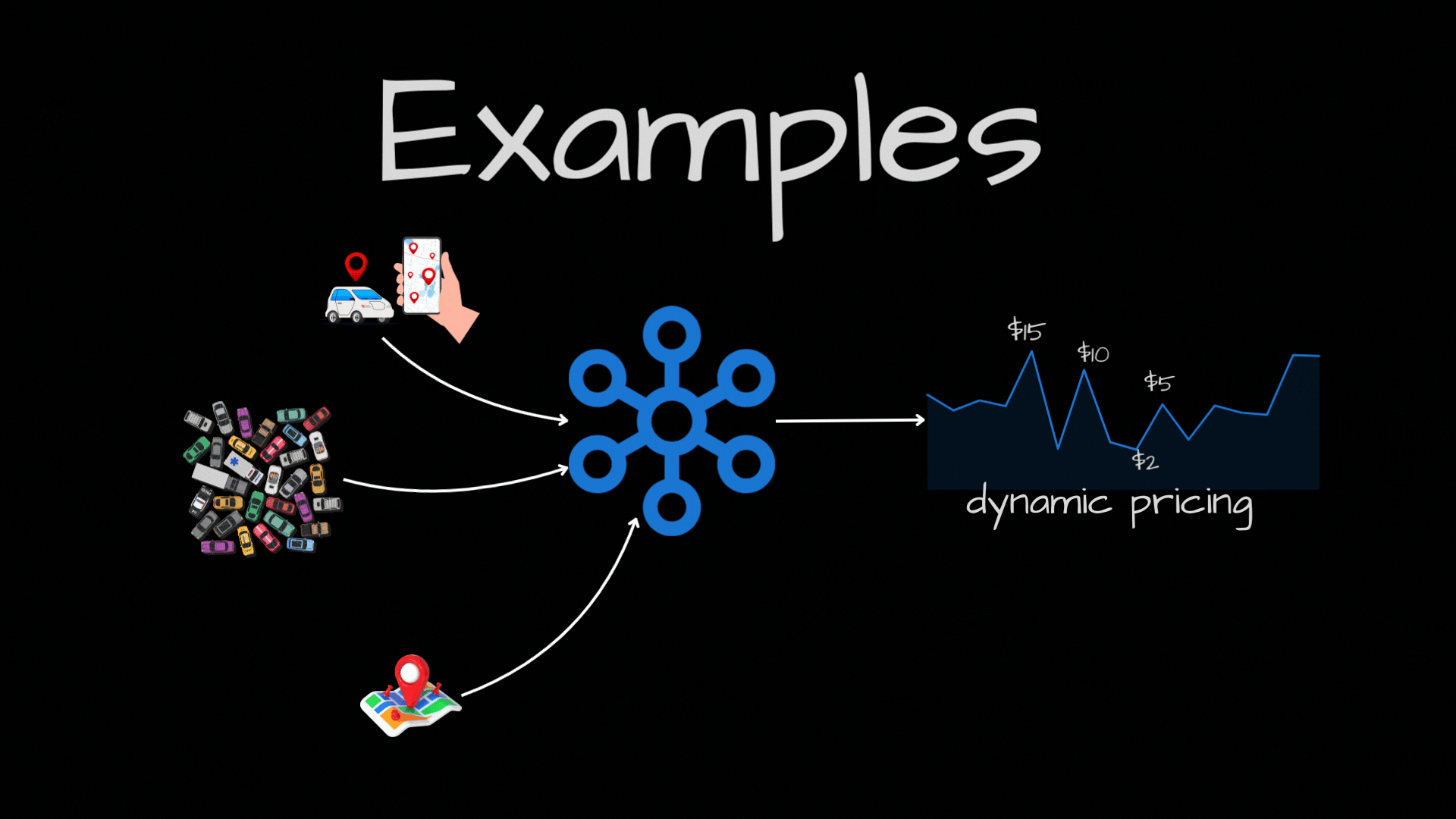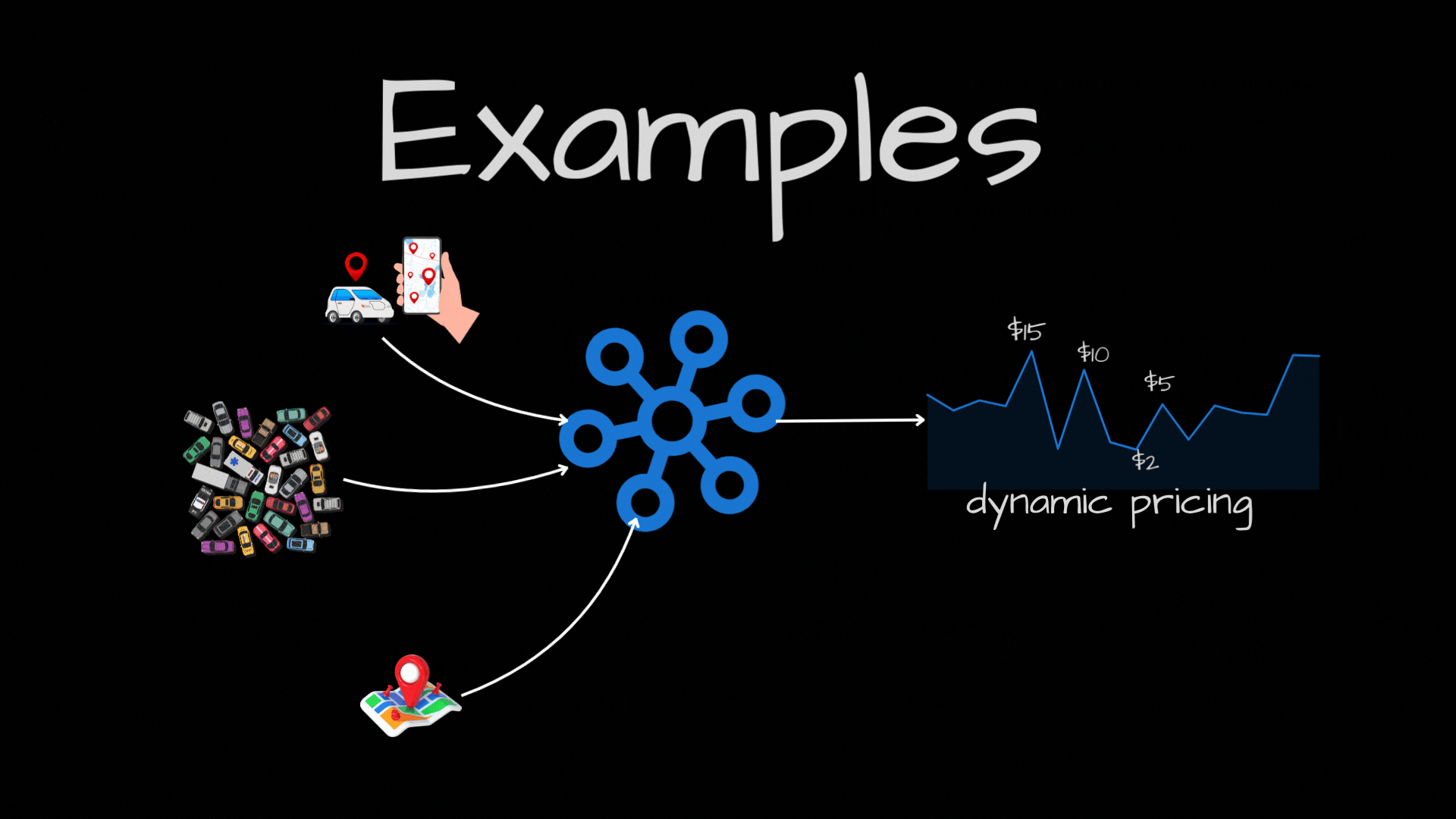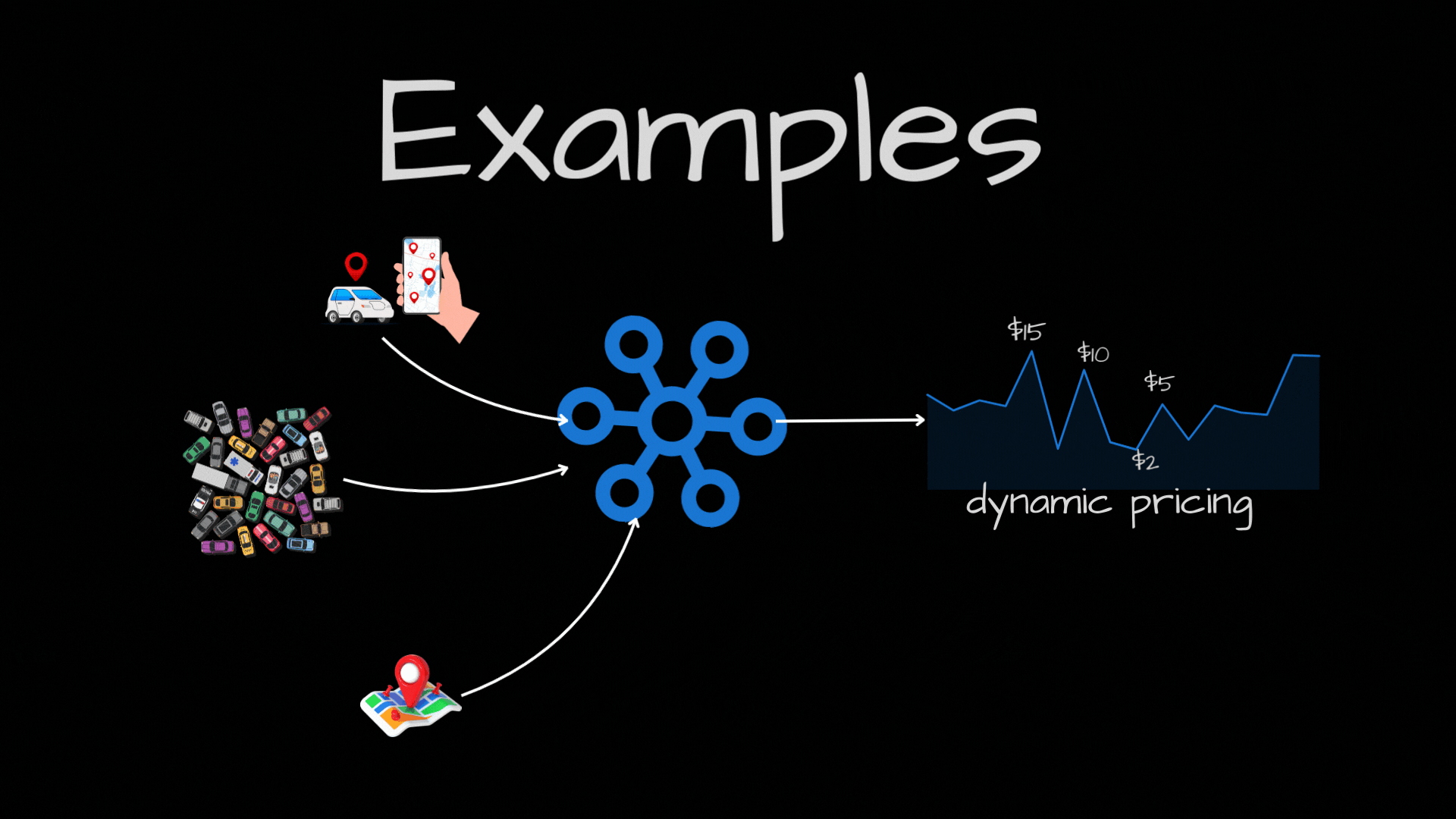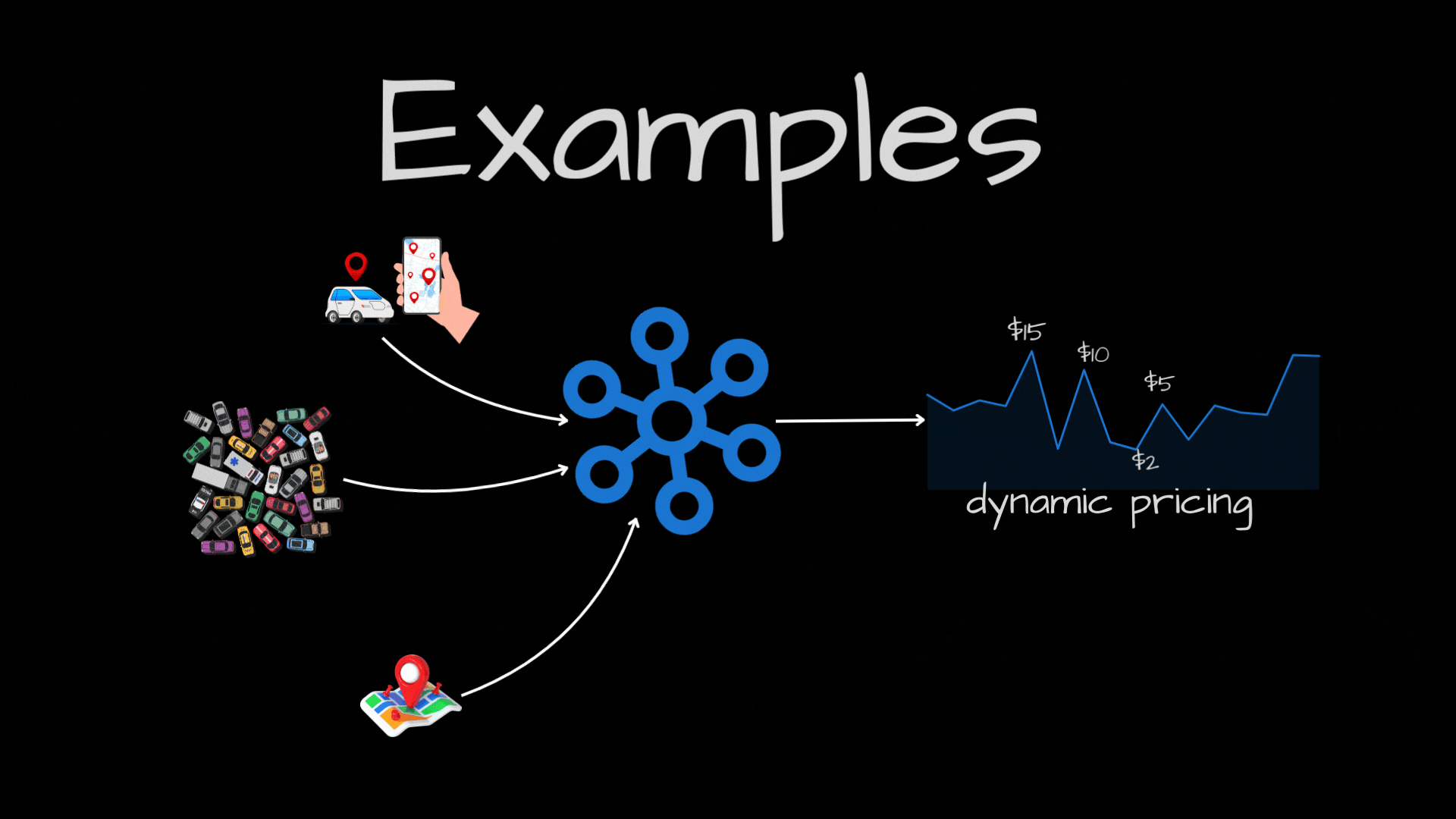
- Credit Card Fraud Detection: Financial institutions use stream processing to monitor transactions and flag fraudulent activity in realtime.

- Predictive Analytics in Retail: Businesses can analyze customer website behavior to understand trends and predict future actions, to manage inventory efficiently all in realtime.

The Evolution of Stream Processing
Stream processing isn't new, having been around for over 20 years. It has significantly evolved alongside advancements in databases and distributed systems. Today, there are powerful streaming databases like RisingWave, and stream processing is becoming increasingly common. Modern stream processing focuses on fault tolerance and large-scale data stream processing.
Comparing Batch and Stream Processing
| Feature | Batch Processing | Stream Processing |
|---|---|---|
| Nature of Data Processing | Processes data in chunks or batches | Processes data continuously as it's received |
| Latency | Inherently high due to data collection and batch processing | Low latency; data is processed as soon as it's available |
| Processing | Scheduled (hourly, daily, weekly) | Continuous and always on |
| Infrastructure Requirements | Significant resources needed for large data volumes | Systems must be always on and resilient to failures |
| Throughput | Good for handling high data volumes regardless of peak periods | Good for real-time data with high throughput |
| Complexity | Simpler; data is readily available in chunks | More complex due to fault tolerance, continuous processing, and potential out-of-orderness or consistency issues |
| Use Cases | ETL jobs, monthly reports | Real-time analytics, fraud detection, live dashboards |
| Error Handling | After the batch is processed completely | Requires immediate error handling, in some cases corrections maybe required later. |
| Tools | Hadoop, Apache Spark | Apache Flink, Kafka Streams, RisingWave |
Choosing Between Batch and Stream Processing
The choice depends on your workload and business requirements. Here are some key factors to consider:
- Latency Requirements: If low latency is critical, stream processing can be really powerful.
- Data Volume: Batch processing might be better suited for very high data volumes, that can be processed periodically and not in realtime.
- Existing Infrastructure: Consider if your current infrastructure can support stream processing.