
- Published on
Stream Processing Concepts
- Authors

- Name
- Kaivalya Apte
- @thegeeknarrator
Note: This blog is sponsored by RisingWave Labs. Checkout RisingWave, and also join the slack channel to connect with the amazing community.
Demystifying Stream Processing Fundamentals: A Detailed Look
This blog delves into notion of time in stream processing, windowing techniques, and strategies for handling out-of-order events in stream processing.
Why Time Matters in Stream Processing
Unlike batch processing that analyzes entire datasets, stream processing deals with continuous streams of data, one record or event at a time. Therefore, understanding time is crucial:
- Event Time: Event time refers to the time recorded at the source where the event is produced. It signifies the time when the event actually occurred. Processing is based on when the event happened, not when it was processed. This means an event can occur now but be processed at a later time, depending on the processing mechanism being used. Event time offers consistency across machines, embedded within the event itself, ensuring deterministic results regardless of the processing machine. However, challenges such as out-of-orderness arise due to differences in event arrival latency.
- Processing Time: Processing time, on the other hand, is the time on the processing machine - the wall clock time on the particular machine executing the stream operation. This means that processing is based on when the event is processed rather than when it occurred. Processing time simplifies processing, eliminating concerns about late events and ensuring low latency and optimal performance without the need for coordination across machines and streams.
Event time is generally preferred for analysis as it reflects true event occurrence. However, processing time can be simpler to work with due to its straightforward nature.
Windowing in Stream Processing
Streams as we know, are unbounded by nature, however "questions" important for a business are based on time. ex. number of clicks grouping by product category, in a 5 min window to identify popular product categories in realtime. Windowing allows us to divide the continuous stream of data into finite chunks for analysis. Without windows, performing calculations or summarizations on continuous data would be challenging and resource-intensive.
There are several types of windows
-
Hopping Window: This window type has a defined window size and hop size. They are based on time intervals. They are fixed size, possibly overlapping windows. Because hopping windows can overlap, and usually they do, a record can belong to more than one such window. for example: every 30 seconds, give me the average user clicks per product area over the last 5 mins.

-
Tumbling Window: They are a special case of hopping windows. In this type, both the window size and hop size are equal, with the window moving or "tumbling" in increments equal to the window size. They are based on time interval, are fixed-size, non-overlapping and gapless windows. As there is no overlap, an event will only be part of exactly one window. for example: analysis of user clicks a product category receives every hour. This helps identify peak shopping hours and how user interest varies throughout the day.

-
Sliding Window: Very similar to hopping windows. The window slides over time or events, continuously counting and aggregating events within the window based on a slide interval. May totally depend on arrival of events and not passing of time. Which means, if there are no new events, the window won't slide and a new window won't be created. There is overlap similar to hopping windows. for example: number of clicks received in the past X minutes for each product category

-
Session Window: This type is used to track user session behavior, defined not by time but by the sequence of incoming events trigger by user activity. for example: running average of user clicks every 1 minute over a window of 5 mins.

Each window type serves different analytical needs, offering ways to manage and analyze data effectively.Depending on how you want to perform the streaming operations over a window, the type of window may play a significant role. For ex. you can chose to avoid creating new windows if there are no new events, OR if you ok with overlapping windows, you can use hopping windows, but if no overlap is tolerable, tumbling windows can be used.
Different stream processing frameworks and platforms provide you easy way to perform these operations and their implementation may wary.
With RisingWave you can create
- Tumbling Window like this
SELECT [ ALL | DISTINCT ] [ * | expression [ AS output_name ] [, expression [ AS output_name ]...] ]
FROM TUMBLE ( table_or_source, start_time, window_size [, offset ] );
and
- Hopping Window like this
SELECT [ ALL | DISTINCT] [ * | expression [ AS output_name ] [, expression [ AS output_name ]...] ]
FROM HOP ( table_or_source, start_time, hop_size, window_size [, offset ]);
You can read more here: Time Windows with RisingWave
And with Flink you can do it like this...
DataStream<T> input = ...;
// tumbling event-time windows
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
DataStream<T> input = ...;
// sliding event-time windows
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
You can read more here: Windows Operator in Flink
Now, lets discuss an important challenge when we decide to use event_time.
Out of Orderness
Events can come out of order in your stream processor. Why? Because even if they were produced in order, they may take separate path to arrive in the stream processor. For ex, if the events end up in two separate partitions and one partition consumer is slower than the other partition.
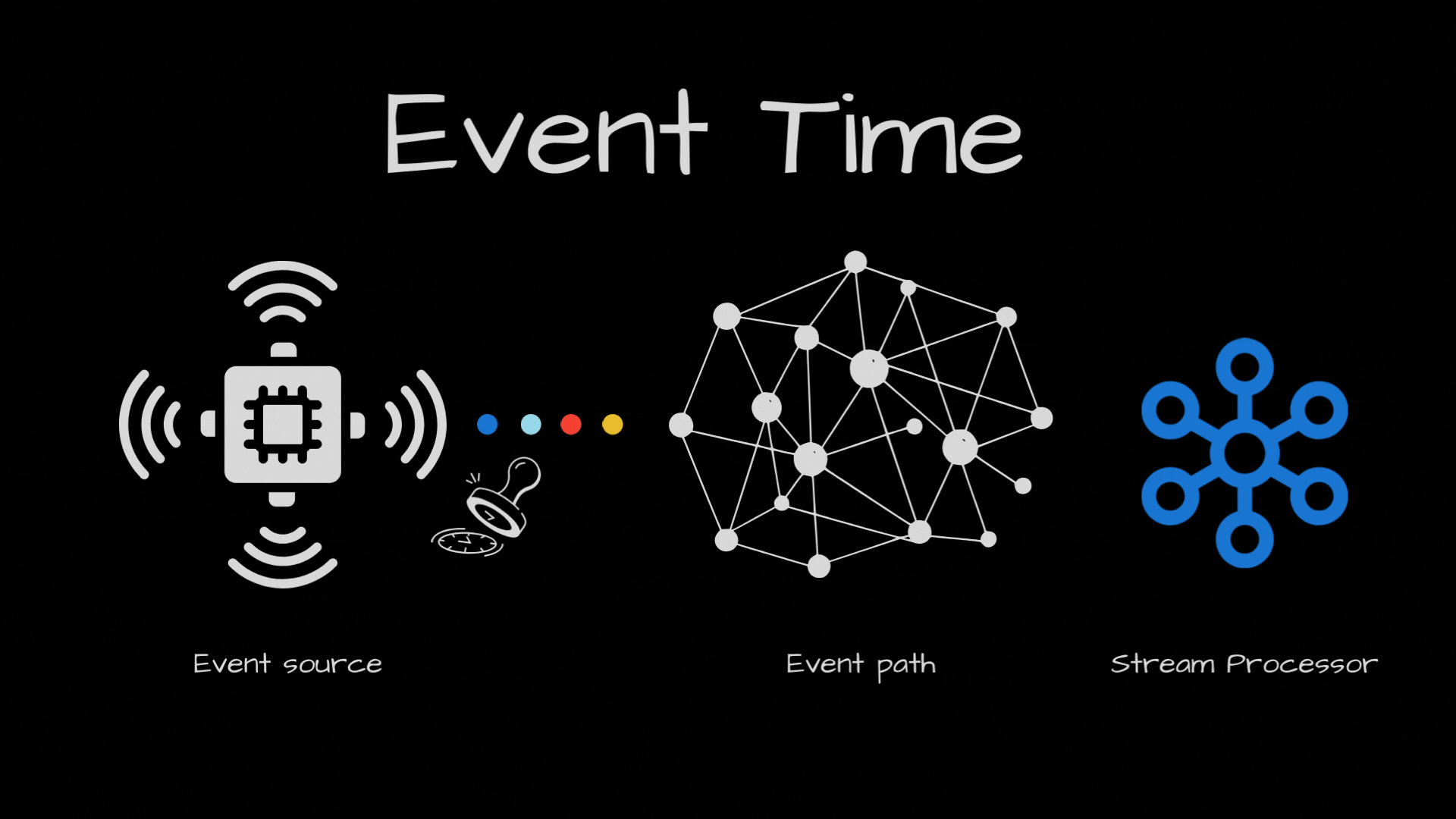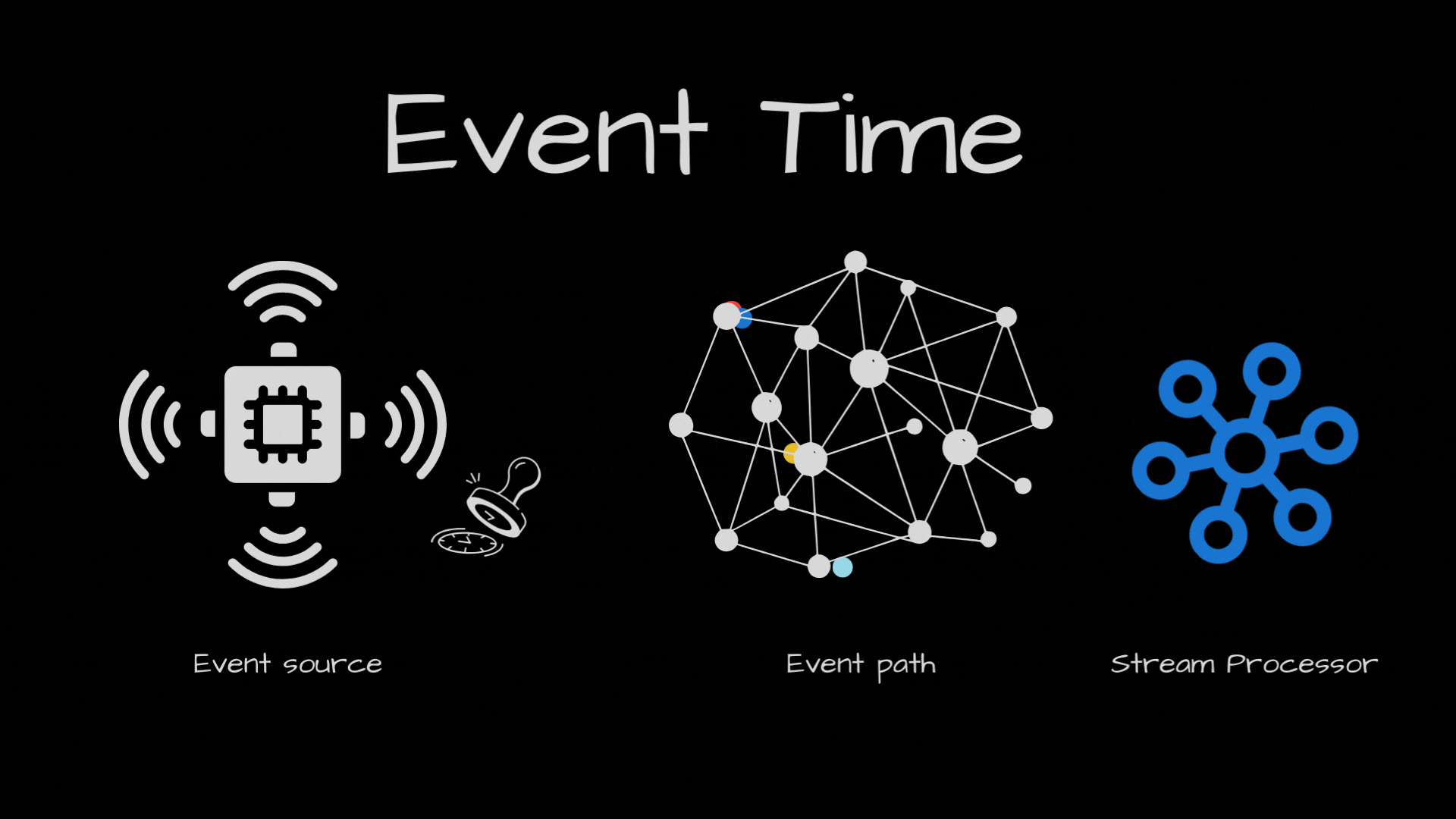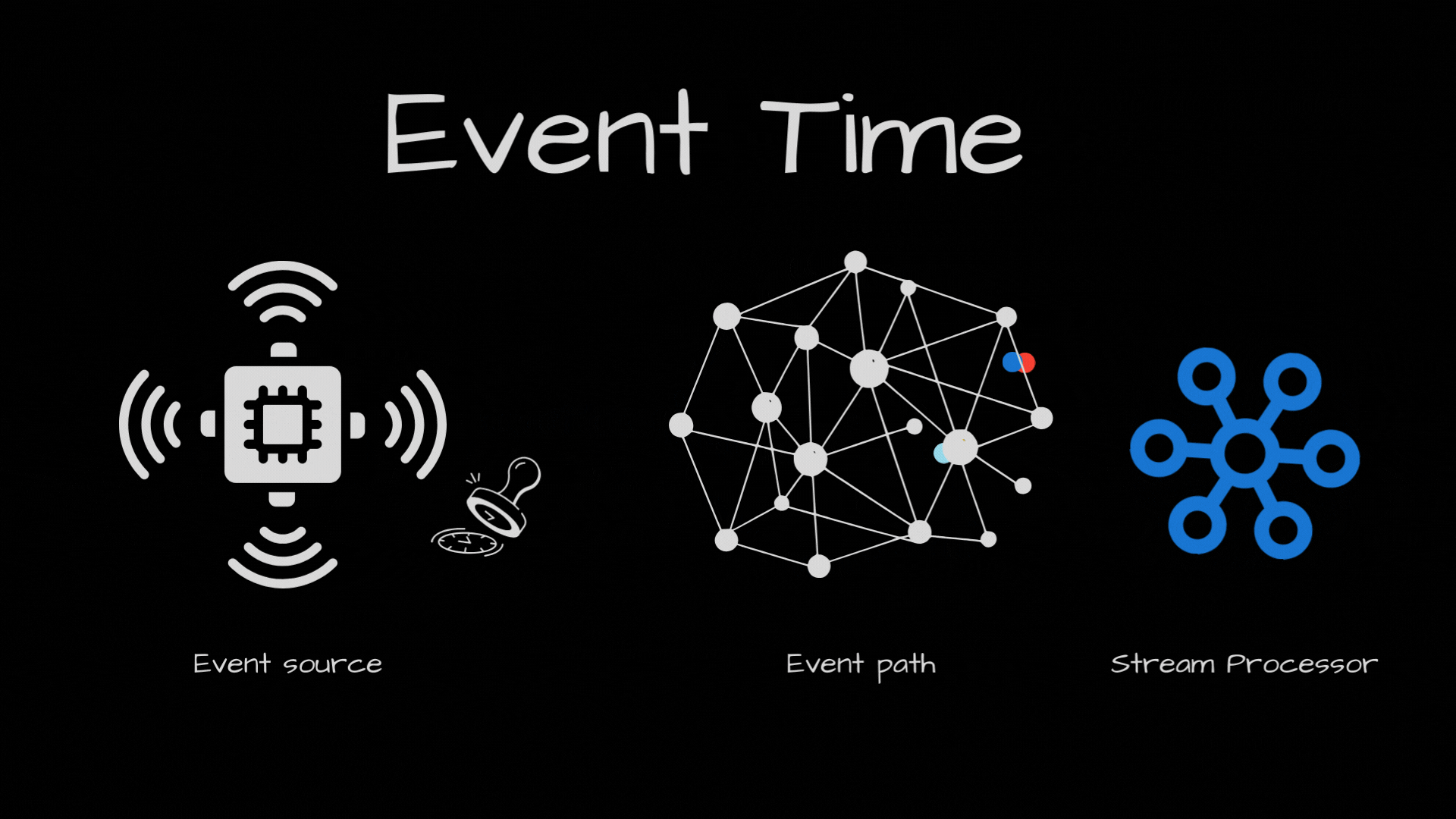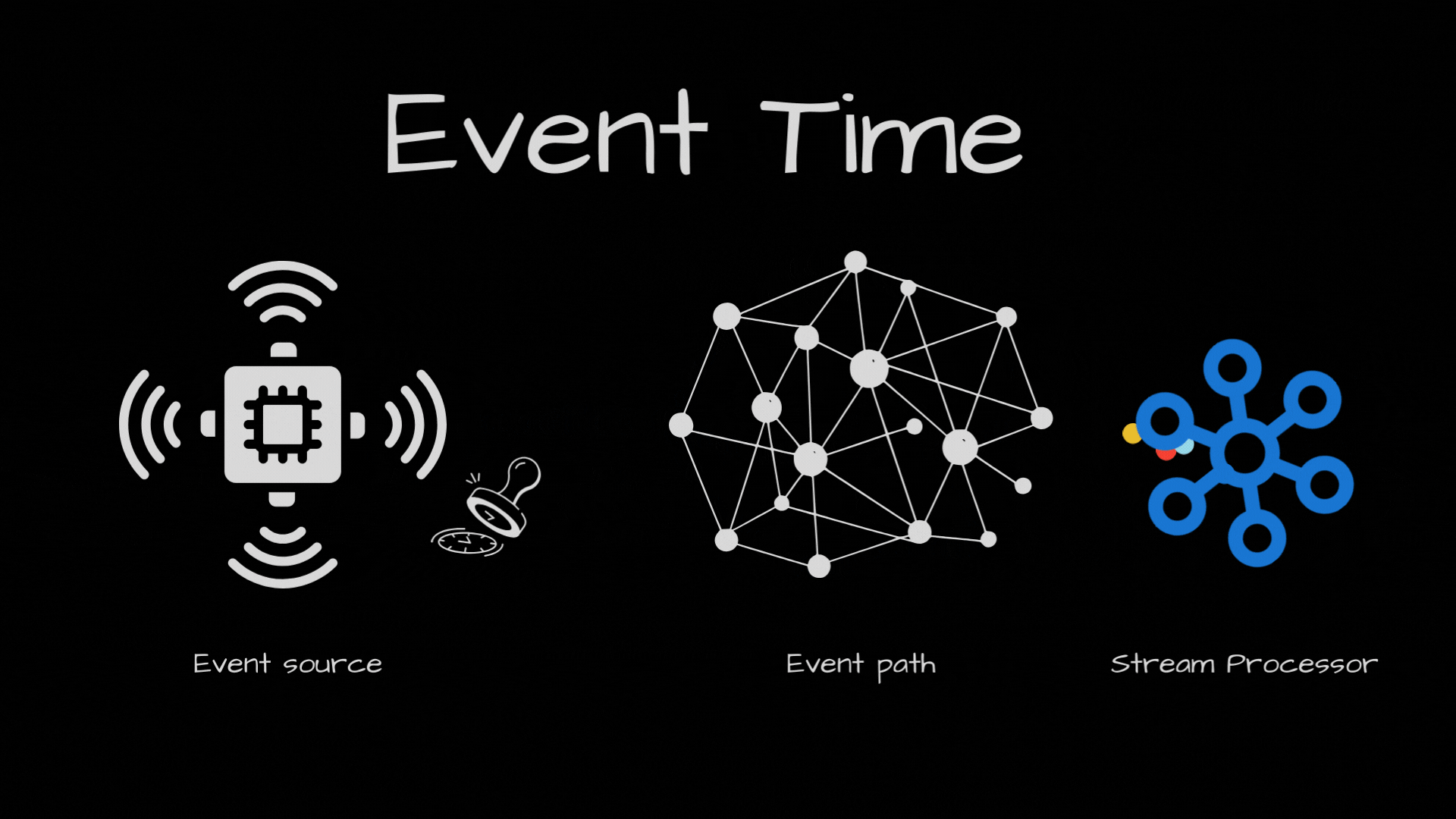
So, with events coming out of order, we have this challenge to solve. Basically we need to keep track of passage of event time in the stream processor, by looking at the events processed so far.
There is a technique that streaming databases like RisingWave and stream processing frameworks like Apache Flink use, called Watermarks. Lets understand how they work.
max_event_time = maximum timestamp observed in the events processed so far. It reflects the highest point in event time that the system has seen.
allowed_lateness = How much time the system should wait for late events.
Watermark a threshold that represents the progress of event time in a system. represents the completeness of event data up to a certain point in event time. Using these watermarks, stream processor can make progress and open new windows, while closing the existing windows.
This is a bit of a challenge to implement in a distributed setup where events are coming from multiple partitions and multiple stream processing nodes are processing them on different machines.
Some frameworks, like Kafka streams do not have watermarks, rather they rely on continuous refinement, which means, if there are late events (out of order), they will just refine the result of that specific window where the event is supposed to be.
I hope you found this blog informative. You can also watch the following video where I talk about all the above concepts.
Don't forget to subscribe to our YouTube channel and share this video with your network to spread knowledge about stream processing.